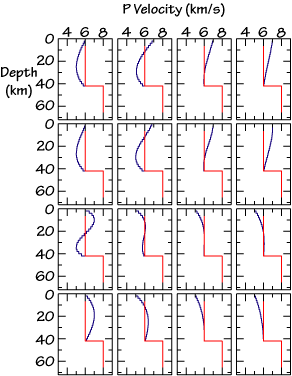
A general flow chart of the inversion procedure is shown to the right. The procedure consists of preparing the observations, constructing an initial model, choosing a smoothness weight parameter, inverting the waveforms and assessing the significance of features in the results. The inversion is really a a search for models fitting the observations using a gradient-based inversion algorithm to map out local minima.
Preparing the Observations
First, you have to get your data ready. Check to see that you don't over sample the observations, usually a sample rate of about 10 samples per second is suitable (delta = 0.1) for studying first-order crustal features. When we were computing the deconvolutions, we used a 20-30 second time shift in the pulse so that we could get a clear idea of the processing noise in the resulting deconvolution. That long signal "leader" is not useful in the inversion, so usually, we cut the signal about 5 seconds in front of the first peak before beginning the inversion.
In general, you should cut the observations such that later arrivals, which may not be generated by the first-order structure of the region are excluded. However, if you make the time series too short, you might have to "zero-pad" the end of the signal.
You can use SAC to insert zeros at the beginning or end of any record. First you issue the "cuterr fill" command, then set a cut window wider than the signal. As you read in the waveform, SAC will fill the signal with zeros out to the window specified by the cut command.
r a_rcvr_ftn.eqr rmean taper w over cuterr fill cut b +0 e +20 r w over cut off
The above commands will add 20 seconds onto the end of the trace (e is the trace end time, e +20 sets the cut to 20 seconds later than e). The "rmean" command may be overkill since the equalization should produce a zero-mean result (the mean of both components was removed before the deconvolution). The taper command is important to insure that no sharp ofsets are introduced when you add zeros to the ends of the trace.